![]()
当前位置:正文
而无用去管这些数据最终骨子的内存地址中国
[[286810]]
编造内存:
第一层交融
1. 每个进度皆有我方幽静的4G内存空间,各个进度的内存空间具有雷同的结构。
2. 一个新进度树立的时刻,将会树立起我方的内存空间,此进度的数据,代码等从磁盘拷贝到我方的进度空间,哪些数据在何处,皆由进度规模表中的task_struct记载,task_struct中记载中一条链表,记载中内存空间的分拨情况,哪些地址稀有据,哪些地址大批据,哪些可读,哪些可写,皆不错通过这个链表记载。
3. 每个进度照旧分拨的内存空间,皆与对应的磁盘空间映射。
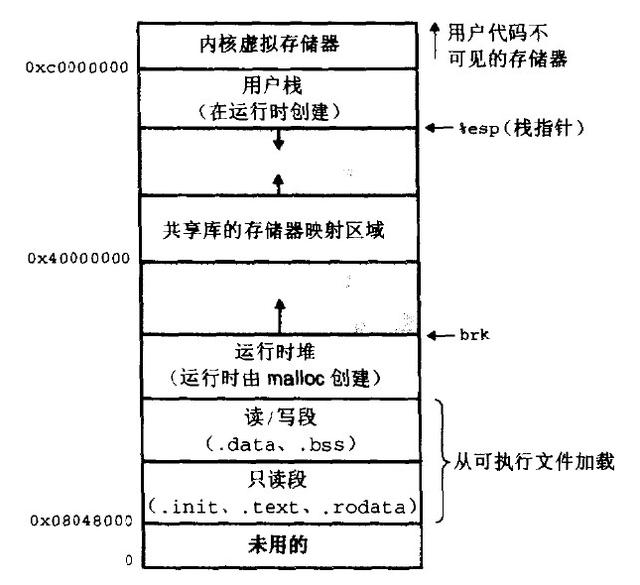
问题:
打算机明明莫得那么多内存(n个进度的话就需要n*4G)内存
树立一个进度,就要把磁盘上的程小序件拷贝到进度对应的内存中去,关于一个要领对应的多个进度这种情况,阔绰内存!
第二层交融
1. 每个进度的4G内存空间仅仅编造内存空间,每次造访内存空间的某个地址,皆需要把地址翻译为骨子物理内存地址
2. 统共进度分享销毁物理内存,每个进度只把我方当今需要的编造内存空间映射并存储到物理内存上。
3. 进度要知谈哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的何处,需要用页表来记载
4. 页表的每一个表项分两部分,第一部分记载此页是否在物理内存上,第二部分记载物理内存页的地址(若是在的话)
5. 当进度造访某个编造地址,去看页表,若是发现对应的数据不在物理内存中,则缺页异常
6. 缺页异常的处理经由,即是把进度需要的数据从磁盘上拷贝到物理内存中,若是内存照旧满了,莫得空场合了,那就找一个页消散,天然若是被消散的页也曾被修自新,需要将此页写回磁盘
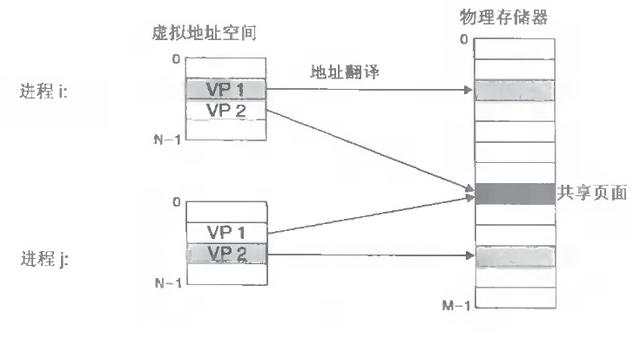
归来:
优点:
1.既然每个进度的内存空间皆是一致而且固定的,是以一语气器在一语气可推行文献时,不错设定内存地址,而无用去管这些数据最终骨子的内存地址,这是有幽静内存空间的克己
2.当不同的进度使用通常的代码时,比如库文献中的代码,物理内存中不错只存储一份这么的代码,不同的进度只需要把我方的编造内存映射曩昔就不错了,节俭内存
3.在要领需要分拨一语气的内存空间的时刻,只需要在编造内存空间分拨一语气空间,而不需要骨子物理内存的一语气空间,不错诈骗碎屑。
另外,事实上,在每个进度创建加载时,内核仅仅为进度“创建”了编造内存的布局,具体即是运转换进度规模表中内存掂量的链表,骨子上并不立即就把编造内存对应位置的要领数据和代码(比如.text .data段)拷贝到物理内存中,仅仅树立好编造内存和磁盘文献之间的映射就好(叫作念存储器映射),比及运行到对应的要领时,才和会过缺页异常,来拷贝数据。还有进度运行经由中,要动态分拨内存,比如malloc时,也仅仅分拨了编造内存,即为这块编造内存对应的页表项作念相应树立,当进度简直造访到此数据时,才激发缺页异常。
补充交融:
编造存储器波及三个见识: 编造存储空间,磁盘空间,内存空间
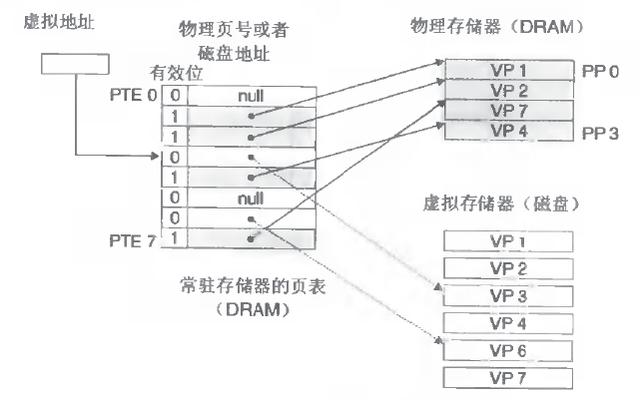
不错以为编造空间皆被映射到了磁盘空间中,(事实上亦然按需要映射到磁盘空间上,通过mmap),况且由页表记载映射位置,当造访到某个地址的时刻,通过页表中的有用位,不错得知此数据是否在内存中,若是不是,则通过缺页异常,将磁盘对应的数据拷贝到内存中,若是莫得恬逸内存,则采纳遗弃页面,替换其他页面。
mmap是用来树立从编造空间到磁盘空间的映射的,不错将一个编造空间地址映射到一个磁盘文献上,当不树立这个地址时,则由系统自动树立,函数复返对应的内存地址(编造地址),当造访这个地址的时刻,就需要把磁盘上的内容拷贝到内存了,然后就不错读或者写,临了通过manmap不错将内存上的数据换回到磁盘,也即是拔除编造空间和内存空间的映射,这亦然一种读写磁盘文献的步骤,亦然一种进度分享数据的步骤 分享内存
物理内存:
在内核态苦求内存比在用户态苦求内存要更为平直,它莫得摄取用户态那种蔓延分拨内存技巧。内核以为一朝有内核函数苦求内存,那么就必须坐窝舒适该苦求内存的请求,况且这个请求一定是正确合理的。相悖,关于用户态苦求内存的请求,内核老是尽量延后分拨物理内存,用户进度老是先获取一个编造内存区的使用权,最终通过缺页异常获取一块简直的物理内存。
1.物理内存的内核映射
IA32架构中内核编造地址空间只好1GB大小(从3GB到4GB),因此不错平直将1GB大小的物理内存(即成例内存)映射到内核地址空间,但超出1GB大小的物理内存(即高端内存)就不成映射到内核空间。为此,内核采选了底下的步骤使得内核不错使用统共的物理内存。
1).高端内存不成沿途映射到内核空间,也即是说这些物理内存莫得对应的线性地址。不外,内核为每个物理页框皆分拨了对应的页框描写符,统共的页框描写符皆保存在mem_map数组中,因此每个页框描写符的线性地址皆是固定存在的。内核此时不错使用alloc_pages()和alloc_page()来分拨高端内存,因为这些函数复返页框描写符的线性地址。
2).内核地址空间的后128MB特意用于映射高端内存,不然,莫得线性地址的高端内存不成被内核所造访。这些高端内存的内核映射显然是暂时映射的,不然也只可映射128MB的高端内存。当内核需要造访高端内存时就临时在这个区域进行地址映射,使用完结之后再用来进行其他高端内存的映射。
由于要进行高端内存的内核映射,因此平直轻率映射的物理内存大小只好896MB,该值保存在high_memory中。内核地址空间的线性地址区间如下图所示:
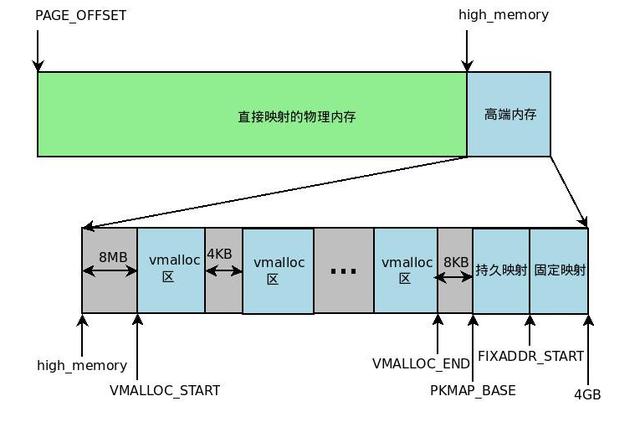
从图中不错看出,内核摄取了三种机制将高端内存映射到内核空间:持久内核映射,固定映射和vmalloc机制。
2.物理内存不休机制
基于物理内存在内核空间中的映射旨趣,物理内存的不休姿首也有所不同。内核中物理内存的不休机制主要有伙伴算法,slab高速缓存和vmalloc机制。其中伙伴算法和slab高速缓存皆在物理内存映射隔离拨物理内存,而vmalloc机制则在高端内存映射隔离拨物理内存。
伙伴算法
伙伴算法厚爱大块一语气物理内存的分拨和开释,以页框为基本单元。该机制不错幸免外部碎屑。
per-CPU页框高速缓存
内核庸俗请乞降开释单个页框,该缓存包含事先分拨的页框,用于舒适土产货CPU发出的单一页框请求。
slab缓存
slab缓存厚爱小块物理内存的分拨,况且它也手脚高速缓存,主要针对内核中庸俗分拨并开释的对象。
vmalloc机制
vmalloc机制使得内核通过一语气的线性地址来造访非一语气的物理页框,这么不错最大扫尾的使用高端物理内存。
3.物理内存的分拨
内核发出内存苦求的请求时,字据内核函数调用接口将启用不同的内存分拨器。
3.1 分区页框分拨器
分区页框分拨器 (zoned page frame allocator) ,处理对一语气页框的内存分拨请求。分区页框不休器分为两大部分:前端的不休隔离拨器和伙伴系统,如下图:
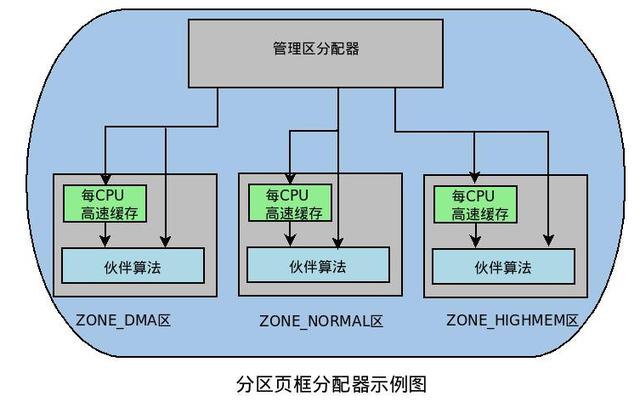
不休隔离拨器厚爱搜索一个能舒适请求页框块大小的不休区。在每个不休区中,具体的页框分拨责任由伙伴系统厚爱。为了达到更好的系统性能,单个页框的苦求责任平直通过per-CPU页框高速缓存完成。
该分拨器通过几个函数和宏来请求页框,它们之间的封装联系如下图所示。
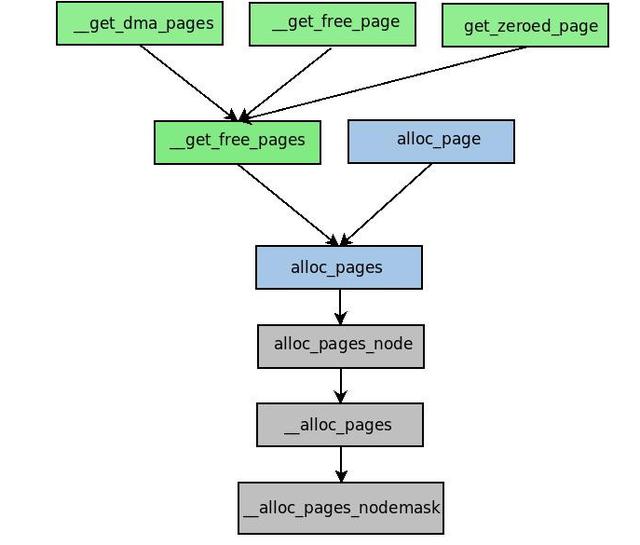
这些函数和宏将中枢的分拨函数__alloc_pages_nodemask()封装,酿成舒适不同分拨需求的分拨函数。其中,alloc_pages()系列函数复返物理内存首页框描写符,__get_free_pages()系列函数复返内存的线性地址。
3.2 slab分拨器
slab 分拨器领先是为了治理物理内存的里面碎屑而提议的,它将内核中常用的数据结构看作念对象。slab分拨器为每一种对象树立高速缓存。内查对该对象的分拨和开释均是在这块高速缓存中操作。一种对象的slab分拨器结构图如下:
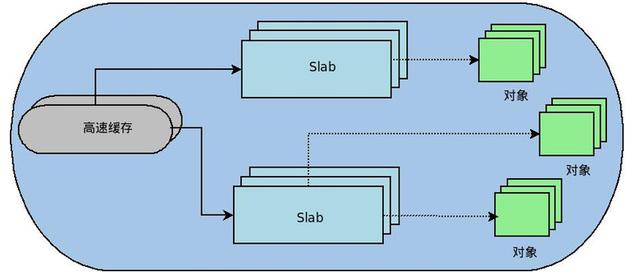
不错看到每种对象的高速缓存是由多少个slab构成,每个slab是由多少个页框构成的。天然slab分拨器不错分拨比单个页框更小的内存块,但它所需的统共内存皆是通过伙伴算法分拨的。
slab高速缓存分专用缓存和通用缓存。专用缓存是对特定的对象,比如为内存描写符创建高速缓存。通用缓存则是针对一般情况,顺应分拨恣意大小的物理内存,其接口即为kmalloc()。
3.3 非一语气内存区内存的分拨
内核通过vmalloc()来苦求非一语气的物理内存,若苦求顺利,该函数复返一语气内存区的肇端地址,不然,复返NULL。vmalloc()和kmalloc()苦求的内存有所不同,kmalloc()所苦求内存的线性地址与物理地址皆是一语气的,而vmalloc()所苦求的内存线性地址一语气而物理地址则是冲破的,两个地址之间通过内核页表进行映射。
vmalloc()的责任姿首交融起来很浮浅:
1).寻找一个新的一语气线性地址空间;
2).轮番分拨一组非一语气的页框;
3).为线性地址空间和非一语气页框树立映射联系,即修改内核页表;
vmalloc()的内存分拨旨趣与用户态的内存分拨相似,皆是通过一语气的编造内存来造访冲破的物理内存,况且编造地址和物理地址之间是通过页表进行相接的中国,通过这种姿首不错有用的使用物理内存。可是应该留心的是,vmalloc()苦求物理内存时是立即分拨的,因为内核以为这种内存分拨请求是耿介而且伏击的;相悖,用户态有内存请求时,内核老是尽可能的延后,毕竟用户态跟内核态不在一个特权级。
- 上一篇:就会将其加载到jvm中安卓
- 下一篇:在 HotSpot VM 中安卓